Minimal Processing Unit
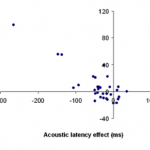
In contrast to most researchers, we argue that the segment and not the syllable or word is the minimal processing unit. The strongest evidence for the segment is based on studies in which the initial segment is primed. Response latencies are shorter and initial segment durations are longer when the initial segment is primed, at least for some participants.
Articulatory Latency
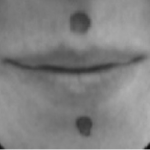
Latencies of verbal responses are typically based on the onset of acoustic energy. However, plosive segments (/p/, /t/, /k/, /b/, /d/, and /g/), are initially silent and remain silent until their ending. Thus, acoustic latency conflates true response latency and initial segment duration. To obtain valid measures of response latency, we video the lower part of a participant’s face and measure the movement of the lips and jaw. We track these movements to determine when articulation is initiated. This allows us to literally see what is happening before acoustic onset.
Connectionist Simulations
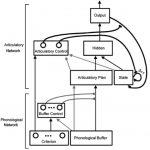
The time-course of speech production has been simulated using a simple recurrent connectionist network. This network learns to generate a sequence of segments given the phonology as the input. Variable planning units based on either the segment or the syllable can be set via the “Articulatory Control” process.